Why
Off-the-shelf LLM chat apps put your conversation, your uploaded files, and your search queries on someone else's server. That's fine for most things. It's not fine when the document is sensitive, the chat is exploratory and half-formed, or the agent has access to real tools. This is the version where everything stays on my machine.
What it does
- Persistent multi-agent chat. Conversations are stored locally and survive across restarts. Each agent has its own system prompt and persona (coding assistant, writing helper, researcher, and so on), and the same UI flips between them.
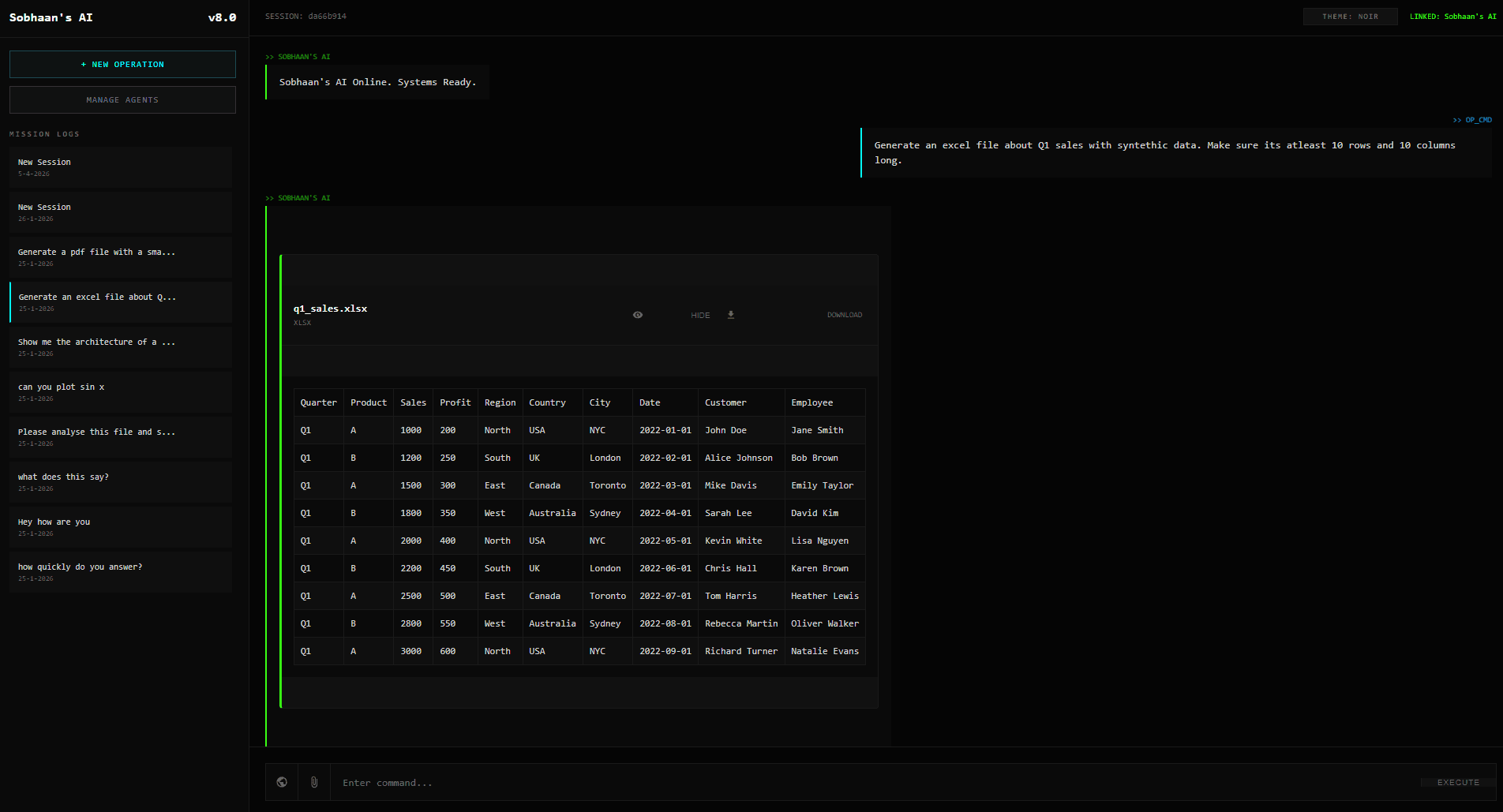
- PDF knowledge bases. Drop a PDF into a chat and the text is extracted (pypdf) and used as context for that agent's responses. No fancy RAG yet (straight context injection), but for a single-document knowledge base that's enough.
- File attachments inline. Same flow for arbitrary files attached to a turn.
- Web search inside conversations. DuckDuckGo integration so the agent can look something up mid-turn. Nothing about the query leaves my network beyond the search itself.
- Fully local LLM. Connects to LM Studio's OpenAI-compatible API, so any model running there is callable. No cloud, no usage tier.
Architecture
- Backend. FastAPI server. Speaks to LM Studio via the standard OpenAI client (LM Studio exposes that interface), so swapping to a different local model server later is mostly a config change.
- Frontend. Plain HTML / CSS / JS, deliberately not a framework. Half the point of this project was to keep the surface area small enough to audit.
- Document processing. pypdf for extraction. PDFs become plain text that the chat handler injects into the next turn's context.
What's next
Better RAG (chunking + retrieval rather than full-document context), streaming responses, multi-document KB per agent. Personal-pace project; gets worked on when there's time.
Stack
Python, FastAPI, LM Studio (OpenAI-compatible API), HTML / CSS / JS, DuckDuckGo Search, pypdf.