
Overview
Group project at Vrije Universiteit Amsterdam (M.Sc. AI) developing a predictive model for Acute Kidney Injury (AKI) in ICU patients with septic shock. Roughly two-thirds of septic shock patients develop AKI, and nearly half do so before they reach the emergency department. A reliable 12-hour-ahead risk signal lets clinicians adjust treatment or initiate renal support sooner.
Research question: which septic shock patients are at risk of developing a specific stage of AKI (0, 1, 2, 3) within the next 12 hours of ICU admission?
Data
AmsterdamUMC database (UMCdb): 23,106 ICU admissions of 20,109 adult patients between 2003 and 2016, with nearly 1.0 billion clinical observations and 5.0 million medication records. Sepsis cohort isolation was a four-step pipeline: leveraging UMCdb's existing sepsis cohort code, filtering to lactate > 2.0 mmol/L, cross-referencing vasopressor administration (Dopamine, Dobutamine, Adrenaline, Noradrenaline), then joining on visit IDs (not patient IDs, since the same patient can have multiple ICU stays).
AKI stage labels are not in UMCdb directly, so we labeled them ourselves from KDIGO 2012 guidelines using creatinine, urine output, and eGFR.
Approach
- Expanding-window training. Train on the first 48 hours of ICU data, predict the next 12-hour window, then slide forward (60h, 72h, 84h, 96h). This matches how clinicians actually re-evaluate patients.
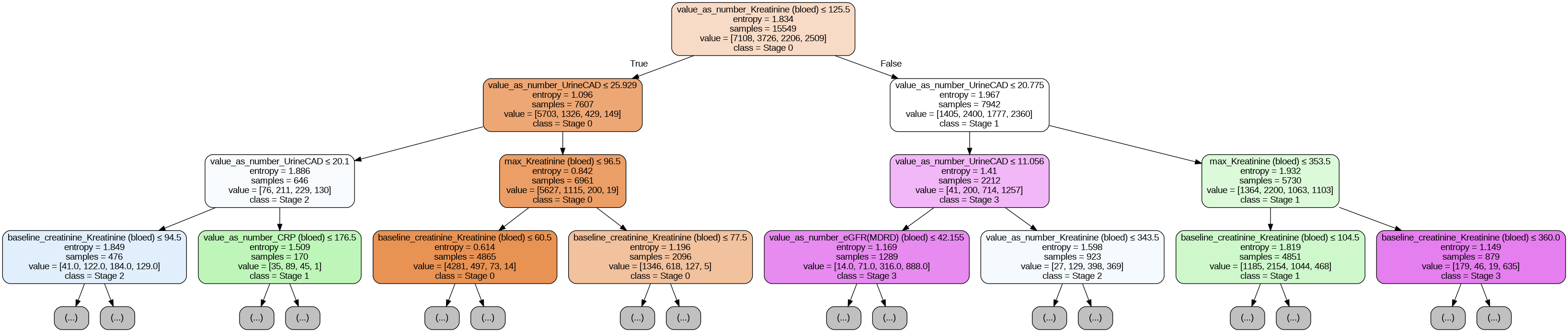
- Two models head-to-head. Decision Tree as the interpretable baseline (clinicians need to be able to read the model), XGBoost as the high-performance comparison.
- Tuning. Optuna with 50 trials per model. Final XGBoost: 237 estimators, max depth 10, lr 0.1609, lambda 3.38, alpha 1.35.
- Explainability. SHAP beeswarm plots and feature importance, plus per-prediction uncertainty estimates so clinical staff can read confidence alongside the prediction.
Key findings
- XGBoost beat the Decision Tree on every metric, statistically significantly (paired t-test, p < 0.05 across accuracy, precision, recall, F1, and calibration). Shapiro-Wilk first confirmed normality of the differences.
- Stage-by-stage performance is very uneven. Stage 0 (no AKI) is the easiest class for both models. Stage 2 AKI is the hardest and degrades both models, likely because it sits between cleaner stage-1 and stage-3 boundaries.
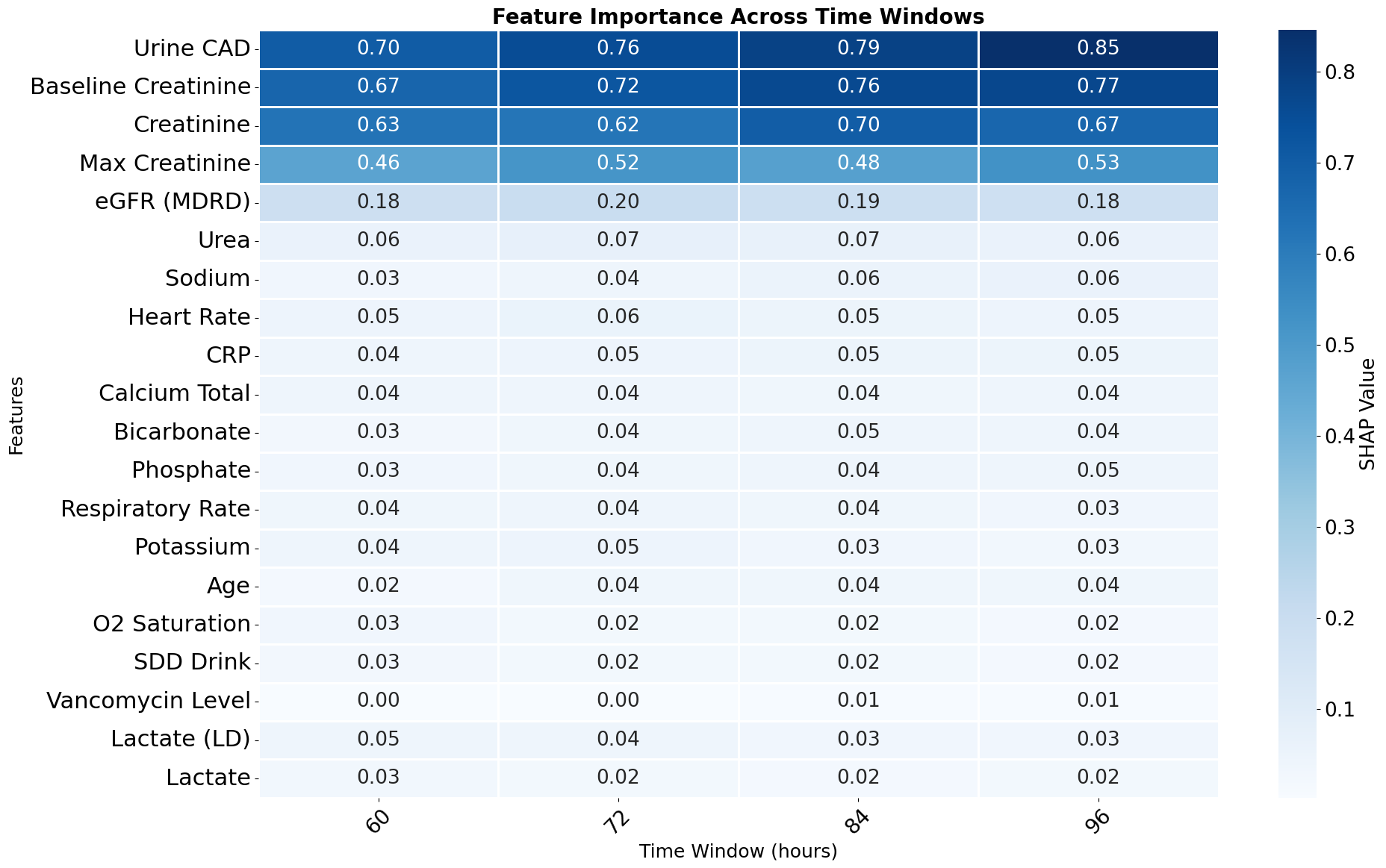
- Feature importance is clinically interpretable and stable across time windows. Urine output, baseline creatinine, and creatinine were consistently the top three predictors from the 60h to 96h windows. The stability matters: if SHAP keeps surfacing the same features that ICU clinicians already trust, the model is more likely to be adopted.
- XGBoost stabilizes by 96h; Decision Tree starts declining. Suggests the gradient-boosted model continues to extract signal from longer ICU histories where the simpler model overfits.
Stack
Python, XGBoost, scikit-learn (Decision Trees), SHAP, Optuna, Pandas, AmsterdamUMC database (UMCdb).

